
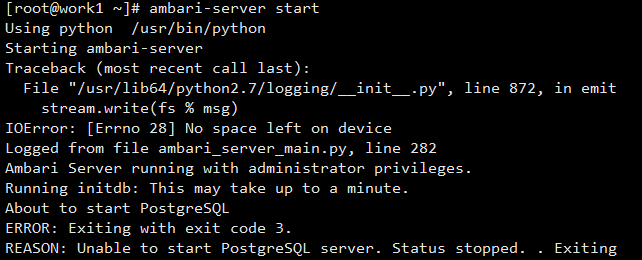
Unable to start PostgreSQL server. Status stopped. . Exiting
bin pg_ctl status
Unable to start PostgreSQL server. Status stopped. . Exiting
bin pg_ctl status
https://51.ruyo.net/16876.html ->>>>> https://github.com/bigleek/UnicomTask
https://51.ruyo.net/16050.html ->>>>>> https://github.com/bigleek/Cloud189Checkin-Actions
github action是github提供的自动化工具能对你参考的代码解析编译构建操作,也可以衍生出其他服务,之前是pro用户才能使用,在GitHub被微软收购后财大气粗的放出的重量级服务,期间很多人滥用action的虚拟机的环境去挖矿
转载 自 掘金: https://juejin.cn/post/6844903573667446797常用的分布式事务解决方案
众所周知,数据库能实现本地事务,也就是在同一个数据库中,你可以允许一组操作要么全都正确执行,要么全都不执行。这里特别强调了本地事务,也就是目前的数据库只能支持同一个数据库中的事务。但现在的系统往往采用微服务架构,业务系统拥有独立的数据库,因此就出现了跨多个数据库的事务需求,这种事务即为“分布式事务”。那么在目前数据库不支持跨库事务的情况下,我们应该如何实现分布式事务呢?本文首先会为大家梳理分布式事务的基本概念和理论基础,然后介绍几种目前常用的分布式事务解决方案。废话不多说,那就开始吧~
转载于 https://www.runningcheese.com/extensions(作者 奔跑中的奶酪 )
扩展之于浏览器,就像 APP 之于智能手机。
浏览器扩展的数量成千上万,但真正好用的并不多,能被用户选择使用的其实也就 50个 左右,而真正安装到浏览器上的也不会超过 20 个。
注意事项
目前centos 7 默认python 环境 为2.7 现在调用 中需要请求比如
https://master:8441/agent/v1/register/master 注册时 会出现问题
技术文档每天都会遇到,条理不够清晰,表达不够准确首先是很难让人理解,同时还会增加沟通的成本
我这边结合阮一峰的博客也结合我最近写文档的思路列一下
两个方向是实践类(包括但不限于 部署,搭建),预研学习类(包括 新技术,技术选型,新趋势)
实践类较为简单
先来个实例网站华为云的部署文档
1.t1
1.1 t2
1.1.1t3
a.
b.
c.
或者
-
-
-
这种来分开步骤和梳理逻辑
同时遇到的问题或者是要集中介绍和梳理的内容可以放在后面开头
问题这种一般先描述现象和问题,然后 列出解决方案不必纠结与 ,把问题讲清楚
在md也尽量使用规范 引用 代码块 需要分开使用不要乱用,对应主要的部分可以加粗高亮
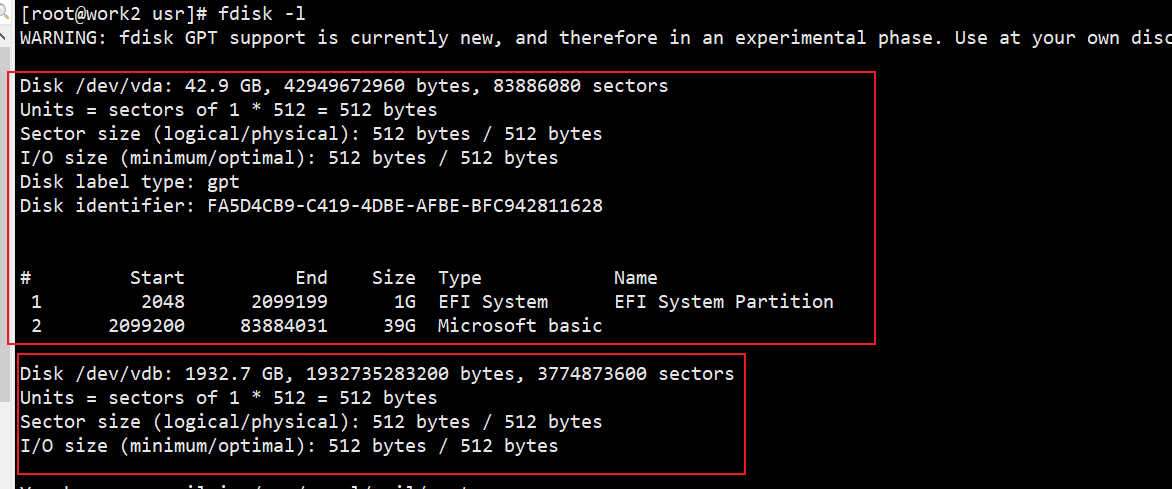
磁盘看到已经能在系统上显示了 但是没有初始化和挂载分区,使用使用 df du 等,命令是看不到具体的情况
看到有 /dev/vdb没有被使用那就去初始化然后去使用
目前的导入导出是 sava/load,export/import ,前者有完整的数据,后者类似于容器的快照,开始搭建时,想直接复制我们服务器中运行的容器,导出后在docker中运行后 一直报
No command specified” from re-imported docker image/container
后面有了解 sava/load 会有完整的数据 但是 export的tar包这个命令将导入镜像文件和参数