
- 1. 1. Redis的单线程和Linux的ePoll特性
- 2. 2. Redis支持的常见结构
- 3. 3. Redis淘汰策略
- 4. 4. Redis集群
- 5. 5. Redis中的缓存雪崩和缓存击穿问题
- 6. 6. 在Spring Boot中使用Redis
- 7. 7. 使用注解
- 8. 8. 结论
- 9. 1. Redis的单线程和Linux的ePoll特性
- 10. 2. Redis支持的常见结构
- 11. 3. Redis淘汰策略
- 12. 4. Redis集群
- 13. 5. Redis中的缓存雪崩和缓存击穿问题
- 14. 6. 在Spring Boot中使用Redis
- 15. 7. 使用注解
- 16. 8. 结论
Redis是一个开源的内存数据存储解决方案,它可以用作缓存、数据库和消息代理。以下是它的主要特点和原理:
- 内存存储:将所有数据存储在内存中,以实现快速读写访问。同时,它支持多种数据结构,如字符串、哈希、列表、集合和有序集合。
- 持久性:Redis支持将数据持久化到磁盘上,以实现数据的可靠存储和恢复。它提供两种不同的持久化选项:快照和日志。
- 高可用性:Redis支持主从复制和哨兵机制,以实现高可用性和故障点转移。
- 分布式:Redis Cluster可以将数据分布在多个节点上,以实现横向扩展和高性能。
- 事务和Lua脚本:重新支持事务和Lua脚本,以实现原子操作和自定义命令。
1. Redis的单线程和Linux的ePoll特性
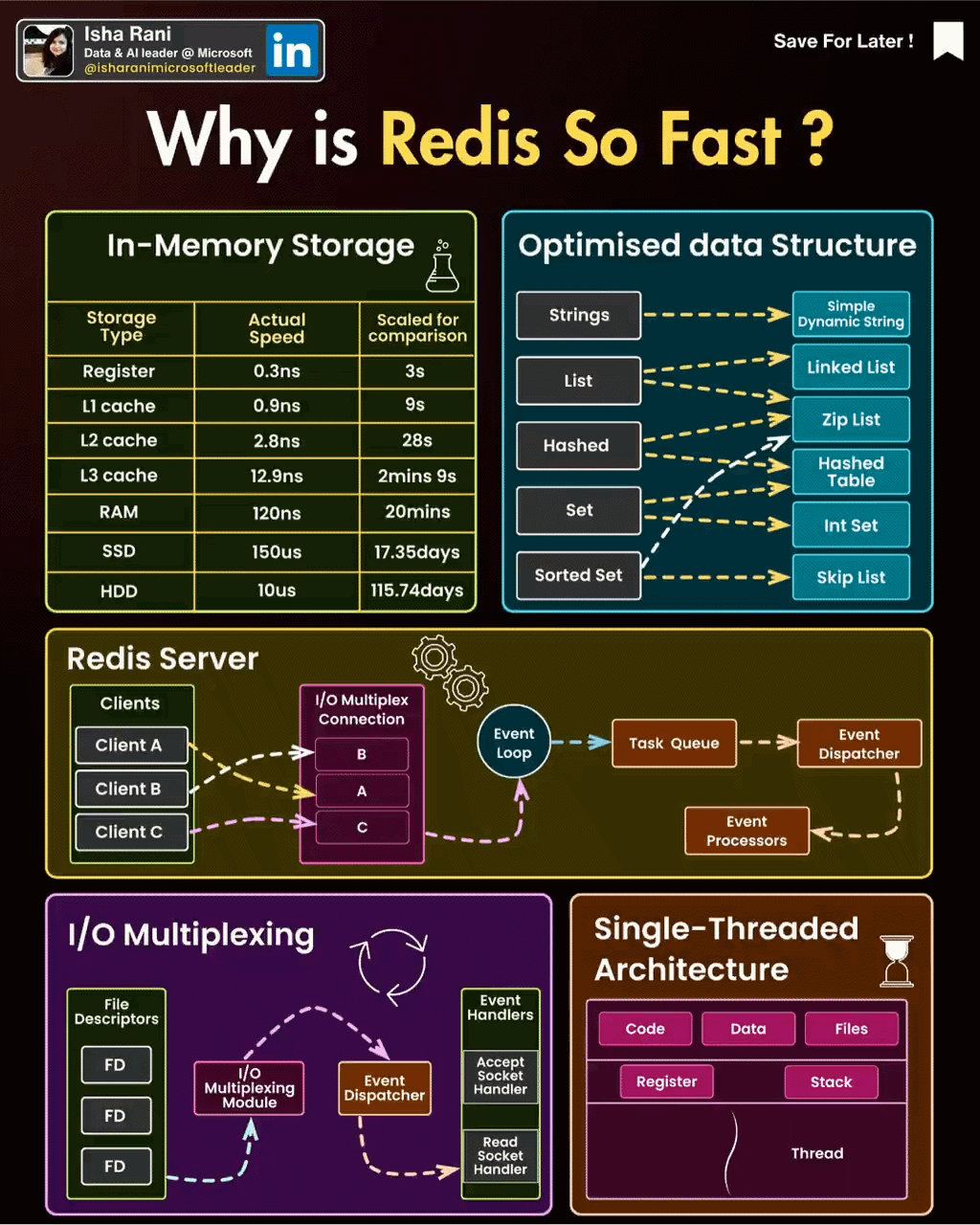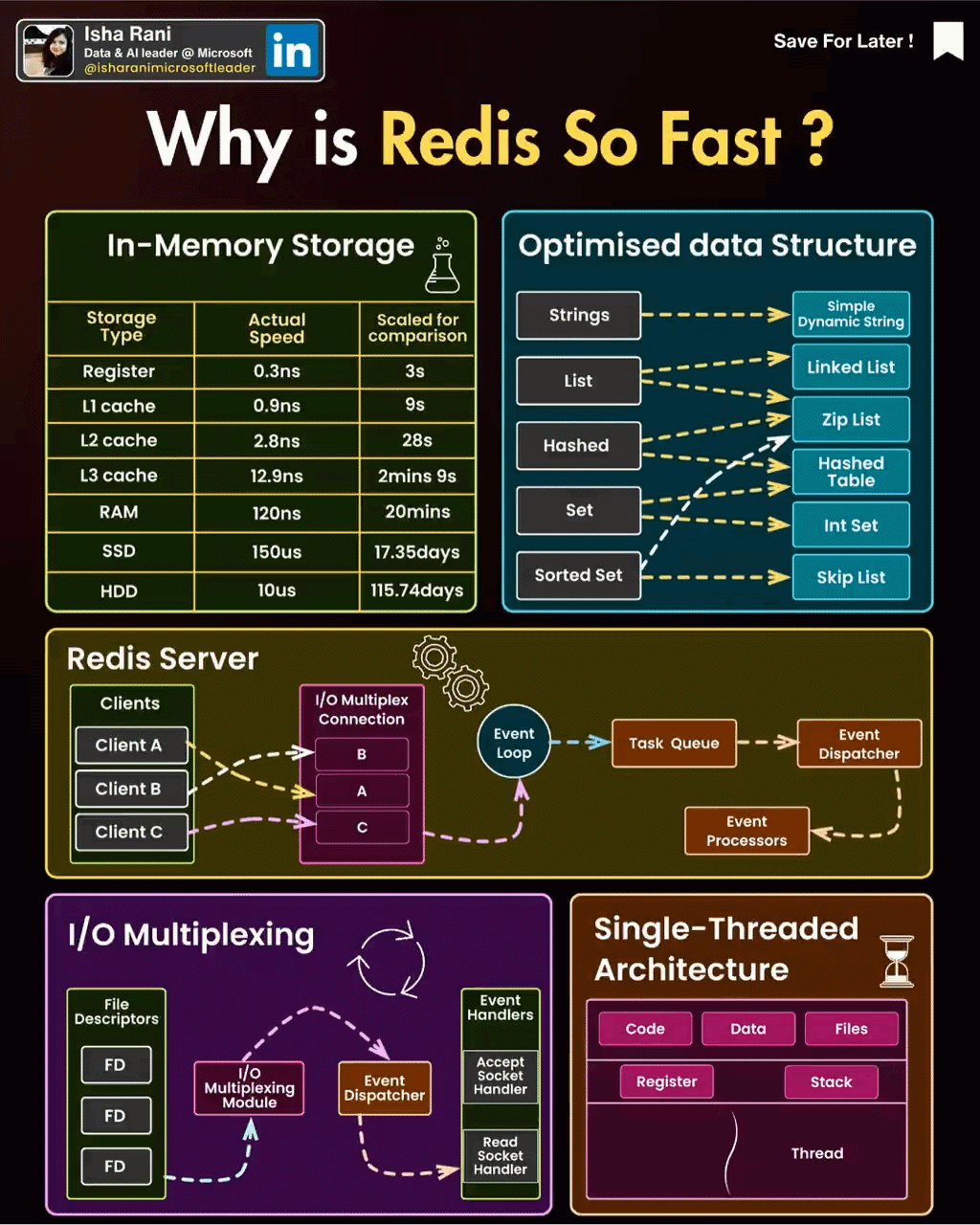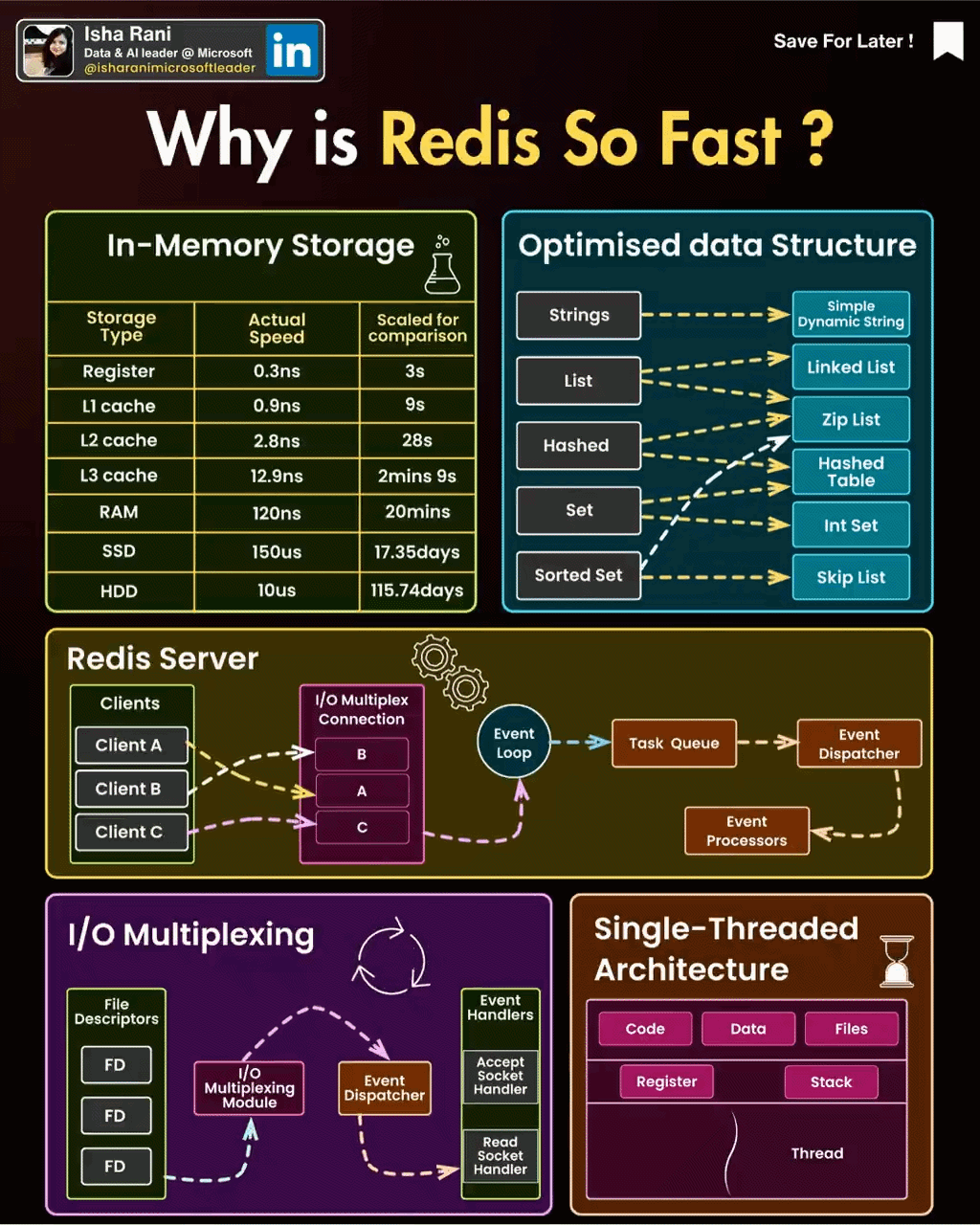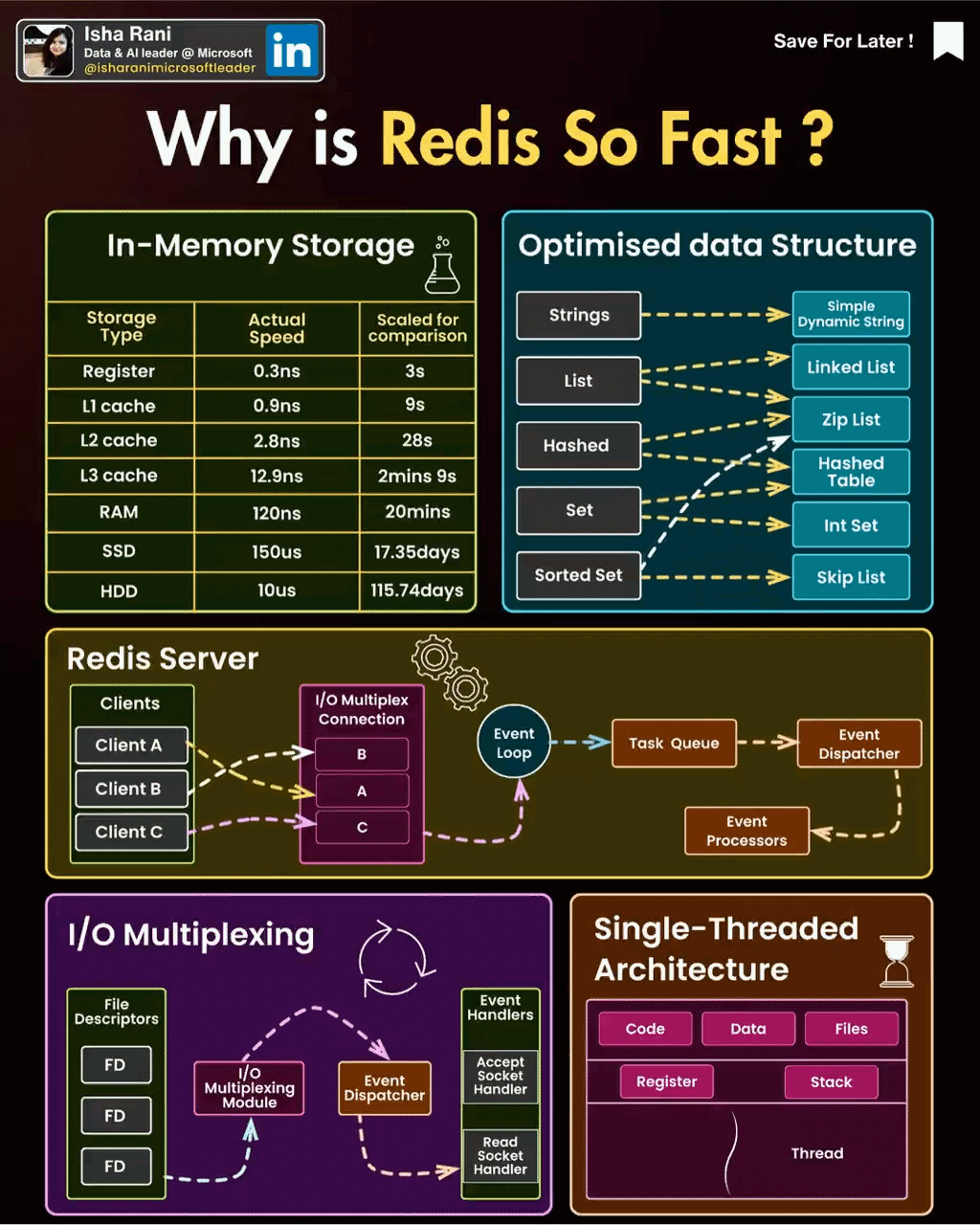
Redis是单线程的,这意味着它使用一个主线程来处理所有客户端请求。它的性能非常高,因为它不需要线程切换的开销,并且可以使用非常少的内存来处理大量的并发连接。另外,Redis使用Linux的ePoll特性来实现异步I/O操作,这使得Redis能够在高负载情况下保持高性能。
在**redis中会有epoll模型是基于异步的io来实现的,**在该模型下每个连接都会有个FileDscript的文件来标示连接情况,连接的客户端有相关的io才会唤醒redis的线程来进行操作
1.1. 缓存数据存储和持久化
RDB(Redis Database):
- RDB 是 Redis 数据的非常紧凑的单文件时间点表示形式。 RDB 文件非常适合备份。 例如,您可能希望在最近 24 小时内每小时归档一次 RDB 文件,并在 30 天内每天保存一个 RDB 快照。 这使您可以在发生灾难时轻松恢复不同版本的数据集。
RDB 非常适合灾难恢复,它是一个紧凑的文件,可以传输到远程数据中心或 Amazon S3(可能是加密的)。
RDB 最大限度地提高了 Redis 的性能,因为 Redis 父进程为了持久化需要做的唯一工作就是派生一个子进程,该子进程将完成其余所有工作。 父进程永远不会执行磁盘 I/O 等操作。
与 AOF 相比,RDB 允许更快地重新启动大数据集。
在副本上,RDB 支持重启和故障转移后的部分重新同步。
- RDB 是 Redis 数据的非常紧凑的单文件时间点表示形式。 RDB 文件非常适合备份。 例如,您可能希望在最近 24 小时内每小时归档一次 RDB 文件,并在 30 天内每天保存一个 RDB 快照。 这使您可以在发生灾难时轻松恢复不同版本的数据集。
AOF日志(Append-Only File):
AOF日志以追加方式记录Redis服务器所执行的写命令,以文本格式保存在一个文件中。
AOF日志允许Redis将写操作追加到文件的末尾,以保持数据的完整性。
AOF日志可以通过配置文件中的appendonly选项来启用和配置。
AOF日志的优点是可以提供更高的数据安全性和持久性,但相比于快照有一定的性能开销。
可以通过配置AOF重写来压缩和优化AOF日志的大小。
2. Redis支持的常见结构
2.1. 数据结构
2.1.1. .字符串(String):
Redis的字符串是一个简单的键值对结构,键是一个字符串,值可以是任意二进制数据。
常用操作:设置值、获取值、增加或减少数值、追加字符串、获取子字符串等。
适用场景:缓存、计数器、分布式锁等。
2.1.2. 哈希(Hash):
Redis的哈希是一个键值对集合,其中键是一个字符串,值是一个字段-值对的映射表。
常用操作:设置字段值、获取字段值、获取所有字段与值、删除字段等。
适用场景:存储对象、存储用户信息、存储配置信息等。
2.1.3. 列表(List):
Redis的列表是一个有序的字符串元素集合,它可以在两端进行插入、删除和查询操作。
常用操作:从列表的左端或右端插入元素、从左端或右端弹出元素、获取指定索引位置的元素等。
适用场景:消息队列、实现最新消息推送、记录操作日志等。
2.1.4. 集合(Set):
Redis的集合是一个无序的字符串元素集合,它不允许重复的元素存在。
常用操作:添加元素、移除元素、判断元素是否存在、求交集、求并集等。
适用场景:标签系统、好友关系、计算共同喜好等。
2.1.5. 有序集合(Sorted Set):
Redis的有序集合是一个排序的字符串元素集合,每个元素都会关联一个分数,通过分数可以进行排序。
常用操作:添加元素、移除元素、根据分数范围获取元素等。
适用场景:排行榜、优先级队列、范围查询等。
2.2. Redis支持其他类型:布隆过滤器、HyperLogLog和Geohash
除了支持字符串、哈希、列表、集合和排序集等常见数据结构外,Redis还支持在某些用例中有用的几种专用数据类型。
2.2.1. 布隆过滤器(Bloom filter)
布隆过滤器是一种概率数据结构,可用于确定元素是否可能存在于集合中。它们在误报(表示元素不在集合中时)是可以接受的,但误报(表示元素不在集合中时)不是可以接受的情况下特别有用。Redis中的布隆过滤器是使用BF. ADD、BF.EXISTS和BF.MADD命令实现的。
2.2.2. HyperLogLog(HyperLogLog)
HyperLogLog是一种用于估计集合基数的概率算法。它为存储集合本身提供了一种节省空间的替代方案,可用于高精度估计非常大的集合中唯一元素的数量。Redis中的HyperLogLog使用PFADD、PFCOUNT和PFMERGE命令实现。
2.2.3. 布谷鸟算法(Cuckoo filter)
检测特定集合是否存在是否存在
2.2.4. 空间类型 geospatial
地理散列是一种以保留接近度的方式将地理坐标编码为字符串的技术。它可用于对一组坐标执行空间查询,例如查找给定点一定半径内的所有坐标。Redis支持通过GEOADD、GEODIST、GEOHASH、GEOPOS和GEORADIUS命令进行地理散列。
通过为这些专门的数据类型提供支持,Redis使开发人员能够凭借其强大的内存数据存储和处理能力解决更广泛的问题。
2.2.5. BitMap类型
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。由于bit是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。
使用示例 位移值和0|1 存储值,例如是否在线,考勤是否打卡
3. Redis淘汰策略

Redis的淘汰策略,根据是否会进行数据淘汰可以把它们分成两类:
- 不进行数据淘汰的策略,只有 noeviction 这一种。
- 会进行淘汰的 7 种其他策略。
会进行淘汰的 7 种策略,我们可以再进一步根据淘汰候选数据集的范围把它们分成两类:
- 在设置了过期时间的数据中进行淘汰,包括 volatile-random、volatile-ttl、volatile-lru、volatile-lfu(Redis 4.0 后新增)四种。
- 在所有数据范围内进行淘汰,包括 allkeys-lru、allkeys-random、allkeys-lfu(Redis 4.0 后新增)三种。
volatile-random、volatile-ttl、volatile-lru、volatile-lfu 四种策略是针对已经设置了过期时间的键值对。到键值对的到期时间到了或者Redis内存使用量达到了maxmemory阈值,Redis会根据这些策略对键值对进行淘汰;
- volatile-ttl 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random 就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru 会使用 LRU (最近最少使用淘汰算法(Least Recently Used)) 算法筛选设置了过期时间的键值对。
- volatile-lfu 会使用 LFU 最不经常使用淘汰算法(Least Frequently Used)选择设置了过期时间的键值对。
备注:
LRU,即:最近最少使用淘汰算法(Least Recently Used)。LRU是淘汰最长时间没有被使用的页面。
LFU,即:最不经常使用淘汰算法(Least Frequently Used)。LFU是淘汰一段时间内,使用次数最少的页面
动手实现 LRU 算法,以及 Caffeine 和 Redis 中的缓存淘汰策略 - 风的姿态 - 博客园
4. Redis集群
一文掌握Redis的三种集群方案 - 个人文章 - SegmentFault 思否
4.1. 主从复制

4.1.1. 主从复制的优缺点
优点:
- master能自动将数据同步到slave,可以进行读写分离,分担master的读压力
- master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点:
- 不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
- master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题
- 难以支持在线扩容,Redis的容量受限于单机配置
4.2. 哨兵模式

优点:
- 哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有
- 哨兵模式下,master挂掉可以自动进行切换,系统可用性更高
缺点:
- 同样也继承了主从模式难以在线扩容的缺点,Redis的容量受限于单机配置
- 需要额外的资源来启动sentinel进程,实现相对复杂一点,同时slave节点作为备份节点不提供服务
4.3. Cluster模式

Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:HASH_SLOT = CRC16(key) % 16384。每一个节点负责维护一部分槽以及槽所映射的键值数据。
5. Redis中的缓存雪崩和缓存击穿问题

5.1. 缓存雪崩
缓存雪崩是指在同一时间,缓存中大量的缓存数据失效,导致大量的请求直接打到了后端数据库上,使得数据库瞬间达到峰值负载,甚至直接宕机。这种情况通常发生在缓存中的数据同时过期时间设置相同,同时失效的情况下。
为了避免缓存雪崩问题,可以采取以下措施:
- 给缓存数据的过期时间加上随机值,避免同时失效。
- 将缓存数据的过期时间分散开来,比如一部分设置为5分钟,一部分设置为10分钟,一部分设置为15分钟,以此类推。
- 设置本地缓存,当缓存失效时,先从本地缓存中获取数据,如果本地缓存没有,则去后端数据库取数据,并将数据再次缓存到本地缓存中。
5.2. 缓存击穿
缓存击穿是指某个热点key在缓存过期的同时,有大量的请求访问该key的时候,这些请求直接穿透到后端数据库,导致数据库瞬间达到峰值负载,甚至直接宕机。
为了避免缓存击穿问题,可以采取以下措施:
- 在缓存数据不存在时,不直接去查询后端数据库,而是先将该key设置为一个特殊的值(如null),在一段时间内(如5秒)不再查询后端数据库,从而避免瞬间大量请求打到数据库上。
- 设置热点数据永不过期,或者过期时间非常长,例如一天、一周、一个月等。
- 设置本地缓存,当缓存失效时,先从本地缓存中获取数据,如果本地缓存没有,则去后端数据库取数据,并将数据再次缓存到本地缓存中。
在使用Redis时需要注意缓存雪崩和缓存击穿问题,采取相应的措施可以避免这些问题的发生,提高系统的稳定性和可靠性。
在Redis中,缓存失效可能有以下几种情况:
- 过期时间到期:当设置了缓存的过期时间后,到期后缓存将会失效。
- 主动删除:使用
DEL命令或者程序中的delete方法,主动删除缓存。 - 内存空间不足:当Rediss内存空间不足时,Rediss会优先淘汰赛掉内存占用较大,使用较少的缓存,以腾出更多的内存空间。
- 内存泄漏:当程序中出现内存泄漏时,会导致缓存失效。
- Redis重启:当Redis服务重启时,缓存也会失效。
为了避免缓存失效,我们可以设置合适的缓存过期时间,定期检查和清理过期缓存,优化Redis的内存使用,以及避免内存泄漏等问题。
6. 在Spring Boot中使用Redis
Redis是一个流行的内存数据存储解决方案,它可以用作缓存、数据库和消息代理。在Spring Boot应用程序中使用Redis可以提高应用程序的性能和可扩展性。在本文中,我们将介绍如何在Spring Boot应用程序中使用Redis。
6.1. .添加Redis依赖
要在Spring Boot应用程序中使用Redis,我们首先需要添加Redis依赖,在Maven项目中,我们可以在pom. xml文件中添加以下依赖项:
1 | <dependency> |
6.2. 配置Redis连接
在我们可以使用Redis之前,我们需要配置Redis连接.在Spring Boot应用程序中,我们可以在application.properties文件中添加以下配置:
1 | spring.redis.host=localhost |
这将配置Redis连接到本地主机的默认端口6379。
6.3. 使用RedisTemplate
Spring Boot提供了一个RedisTemplate类,它是一个用于与Redis交互的高级API。我们可以使用RedisTemplate来执行Redis操作,如存储、检索和删除数据。以下是一个使用RedisTemplate执行Redis操作的示例:
1 | @Autowired |
在上面的示例中,我们注入了一个RedisTemplate对象,并使用它来存储和检索数据。我们使用opsForValue()方法来访问Redis值操作,如设置和获取值。
7. 使用注解
除了使用RedisTemplate之外,Spring Boot还提供了一些注解,可以更轻松地使用Redis。例如,我们可以使用@Cacheable注解将方法的结果缓存到Redis中,从而加快方法的执行速度。以下是一个使用@Cacheable注解的示例:
1 | @Cacheable(value = "users", key = "#userId") |
在上面的示例中,我们使用@Cache able注解将User By Id方法的结果缓存到名为”user”的Red is缓存中,缓存键为rId参数。
7.1. 常见客户端比较 lettuce ,redisson,jedis

| 特性 | Lettuce | Redisson | Jedis |
|---|---|---|---|
| 完整性 | Lettuce 是一个可扩展的线程安全 Redis 客户端,适用于同步、异步和反应式使用。 如果多个线程避免阻塞和事务性操作(例如 BLPOP 和 MULTI/EXEC),则它们可以共享一个连接。 Lettuce是用netty构建的。 支持高级 Redis 功能,例如 Sentinel、集群、管道、自动重新连接和 Redis 数据模型。 | Redisson提供了完整的Redis协议支持,基于Netty 框架,并在其基础上封装了更丰富的特性,如分布式锁、分布式集合等.线程安全的实现 支持Redis复制、Redis集群、Redis哨兵、Redis主从、Redis单机、Redis代理、Redis多集群设置 | Jedis提供了基本的Redis协议支持,但支持高级功能如Pipelining、Miscellaneous、Cluster、Pub/Sub等。Redis 官方推荐的Java客户端 |
| 连接管理 | 支持连接池和连接自动恢复机制,具有更好的连接管理能力。 | 支持连接池和连接自动恢复机制,具有较好的连接管理能力。 | 支持连接池,但没有连接自动恢复机制, |
| 异步操作 | 提供完善的异步操作接口和功能,支持Reactive编程模型。 | 提供完善的异步操作接口和功能,支持Reactive编程模型。 | 不支持异步操作,只能使用同步方式进行操作。 |
| 分布式功能 | 支持Redis Sentinel和Redis Cluster,可以使用Lettuce进行分布式部署。 | 提供了丰富的分布式功能,如分布式锁、分布式集合、分布式对象等。 | 不支持Redis Sentinel和Redis Cluster,不适用于分布式部署。 |
| 扩展性 | 提供了较好的扩展性,用户可以自定义编解码器、连接池实现等。 | 提供了较好的扩展性,用户可以自定义编解码器、连接管理器等。 | 较难进行扩展,功能相对固定。 |
| 社区活跃度 | 拥有活跃的开源社区,稳定更新并提供技术支持。 | 拥有活跃的开源社区,稳定更新并提供技术支持。 | 拥有较为活跃的开源社区,但相对于Lettuce和Redisson稍显不足。 |
| https://github.com/lettuce-io/lettuce-core最新版本是 | https://github.com/redisson/redisson 最新版是 3.23.4 | https://github.com/redis/jedis 最近版本是5.0.0 |
8. 结论

Redis是一个开源的内存数据存储解决方案,它可以用作缓存、数据库和消息代理。以下是它的主要特点和原理:
- 内存存储:将所有数据存储在内存中,以实现快速读写访问。同时,它支持多种数据结构,如字符串、哈希、列表、集合和有序集合。
- 持久性:Redis支持将数据持久化到磁盘上,以实现数据的可靠存储和恢复。它提供两种不同的持久化选项:快照和日志。
- 高可用性:Redis支持主从复制和哨兵机制,以实现高可用性和故障点转移。
- 分布式:Redis Cluster可以将数据分布在多个节点上,以实现横向扩展和高性能。
- 事务和Lua脚本:重新支持事务和Lua脚本,以实现原子操作和自定义命令。
1. Redis的单线程和Linux的ePoll特性
Redis是单线程的,这意味着它使用一个主线程来处理所有客户端请求。它的性能非常高,因为它不需要线程切换的开销,并且可以使用非常少的内存来处理大量的并发连接。另外,Redis使用Linux的ePoll特性来实现异步I/O操作,这使得Redis能够在高负载情况下保持高性能。
在**redis中会有epoll模型是基于异步的io来实现的,**在该模型下每个连接都会有个FileDscript的文件来标示连接情况,连接的客户端有相关的io才会唤醒redis的线程来进行操作
1.1. 缓存数据存储和持久化
RDB(Redis Database):
- RDB 是 Redis 数据的非常紧凑的单文件时间点表示形式。 RDB 文件非常适合备份。 例如,您可能希望在最近 24 小时内每小时归档一次 RDB 文件,并在 30 天内每天保存一个 RDB 快照。 这使您可以在发生灾难时轻松恢复不同版本的数据集。
RDB 非常适合灾难恢复,它是一个紧凑的文件,可以传输到远程数据中心或 Amazon S3(可能是加密的)。
RDB 最大限度地提高了 Redis 的性能,因为 Redis 父进程为了持久化需要做的唯一工作就是派生一个子进程,该子进程将完成其余所有工作。 父进程永远不会执行磁盘 I/O 等操作。
与 AOF 相比,RDB 允许更快地重新启动大数据集。
在副本上,RDB 支持重启和故障转移后的部分重新同步。
- RDB 是 Redis 数据的非常紧凑的单文件时间点表示形式。 RDB 文件非常适合备份。 例如,您可能希望在最近 24 小时内每小时归档一次 RDB 文件,并在 30 天内每天保存一个 RDB 快照。 这使您可以在发生灾难时轻松恢复不同版本的数据集。
AOF日志(Append-Only File):
AOF日志以追加方式记录Redis服务器所执行的写命令,以文本格式保存在一个文件中。
AOF日志允许Redis将写操作追加到文件的末尾,以保持数据的完整性。
AOF日志可以通过配置文件中的appendonly选项来启用和配置。
AOF日志的优点是可以提供更高的数据安全性和持久性,但相比于快照有一定的性能开销。
可以通过配置AOF重写来压缩和优化AOF日志的大小。
2. Redis支持的常见结构
2.1. 数据结构
2.1.1. .字符串(String):
Redis的字符串是一个简单的键值对结构,键是一个字符串,值可以是任意二进制数据。
常用操作:设置值、获取值、增加或减少数值、追加字符串、获取子字符串等。
适用场景:缓存、计数器、分布式锁等。
2.1.2. 哈希(Hash):
Redis的哈希是一个键值对集合,其中键是一个字符串,值是一个字段-值对的映射表。
常用操作:设置字段值、获取字段值、获取所有字段与值、删除字段等。
适用场景:存储对象、存储用户信息、存储配置信息等。
2.1.3. 列表(List):
Redis的列表是一个有序的字符串元素集合,它可以在两端进行插入、删除和查询操作。
常用操作:从列表的左端或右端插入元素、从左端或右端弹出元素、获取指定索引位置的元素等。
适用场景:消息队列、实现最新消息推送、记录操作日志等。
2.1.4. 集合(Set):
Redis的集合是一个无序的字符串元素集合,它不允许重复的元素存在。
常用操作:添加元素、移除元素、判断元素是否存在、求交集、求并集等。
适用场景:标签系统、好友关系、计算共同喜好等。
2.1.5. 有序集合(Sorted Set):
Redis的有序集合是一个排序的字符串元素集合,每个元素都会关联一个分数,通过分数可以进行排序。
常用操作:添加元素、移除元素、根据分数范围获取元素等。
适用场景:排行榜、优先级队列、范围查询等。
2.2. Redis支持其他类型:布隆过滤器、HyperLogLog和Geohash
除了支持字符串、哈希、列表、集合和排序集等常见数据结构外,Redis还支持在某些用例中有用的几种专用数据类型。
2.2.1. 布隆过滤器(Bloom filter)
布隆过滤器是一种概率数据结构,可用于确定元素是否可能存在于集合中。它们在误报(表示元素不在集合中时)是可以接受的,但误报(表示元素不在集合中时)不是可以接受的情况下特别有用。Redis中的布隆过滤器是使用BF. ADD、BF.EXISTS和BF.MADD命令实现的。
2.2.2. HyperLogLog(HyperLogLog)
HyperLogLog是一种用于估计集合基数的概率算法。它为存储集合本身提供了一种节省空间的替代方案,可用于高精度估计非常大的集合中唯一元素的数量。Redis中的HyperLogLog使用PFADD、PFCOUNT和PFMERGE命令实现。
2.2.3. 布谷鸟算法(Cuckoo filter)
检测特定集合是否存在是否存在
2.2.4. 空间类型 geospatial
地理散列是一种以保留接近度的方式将地理坐标编码为字符串的技术。它可用于对一组坐标执行空间查询,例如查找给定点一定半径内的所有坐标。Redis支持通过GEOADD、GEODIST、GEOHASH、GEOPOS和GEORADIUS命令进行地理散列。
通过为这些专门的数据类型提供支持,Redis使开发人员能够凭借其强大的内存数据存储和处理能力解决更广泛的问题。
2.2.5. BitMap类型
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。由于bit是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。

使用示例 位移值和0|1 存储值,例如是否在线,考勤是否打卡

3. Redis淘汰策略
Redis的淘汰策略,根据是否会进行数据淘汰可以把它们分成两类:
- 不进行数据淘汰的策略,只有 noeviction 这一种。
- 会进行淘汰的 7 种其他策略。
会进行淘汰的 7 种策略,我们可以再进一步根据淘汰候选数据集的范围把它们分成两类:
- 在设置了过期时间的数据中进行淘汰,包括 volatile-random、volatile-ttl、volatile-lru、volatile-lfu(Redis 4.0 后新增)四种。
- 在所有数据范围内进行淘汰,包括 allkeys-lru、allkeys-random、allkeys-lfu(Redis 4.0 后新增)三种。
volatile-random、volatile-ttl、volatile-lru、volatile-lfu 四种策略是针对已经设置了过期时间的键值对。到键值对的到期时间到了或者Redis内存使用量达到了maxmemory阈值,Redis会根据这些策略对键值对进行淘汰;
- volatile-ttl 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random 就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru 会使用 LRU (最近最少使用淘汰算法(Least Recently Used)) 算法筛选设置了过期时间的键值对。
- volatile-lfu 会使用 LFU 最不经常使用淘汰算法(Least Frequently Used)选择设置了过期时间的键值对。
备注:
LRU,即:最近最少使用淘汰算法(Least Recently Used)。LRU是淘汰最长时间没有被使用的页面。
LFU,即:最不经常使用淘汰算法(Least Frequently Used)。LFU是淘汰一段时间内,使用次数最少的页面
动手实现 LRU 算法,以及 Caffeine 和 Redis 中的缓存淘汰策略 - 风的姿态 - 博客园
4. Redis集群
一文掌握Redis的三种集群方案 - 个人文章 - SegmentFault 思否
4.1. 主从复制
4.1.1. 主从复制的优缺点
优点:
- master能自动将数据同步到slave,可以进行读写分离,分担master的读压力
- master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点:
- 不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
- master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题
- 难以支持在线扩容,Redis的容量受限于单机配置
4.2. 哨兵模式
优点:
- 哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有
- 哨兵模式下,master挂掉可以自动进行切换,系统可用性更高
缺点:
- 同样也继承了主从模式难以在线扩容的缺点,Redis的容量受限于单机配置
- 需要额外的资源来启动sentinel进程,实现相对复杂一点,同时slave节点作为备份节点不提供服务
4.3. Cluster模式
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:HASH_SLOT = CRC16(key) % 16384。每一个节点负责维护一部分槽以及槽所映射的键值数据。
5. Redis中的缓存雪崩和缓存击穿问题
5.1. 缓存雪崩
缓存雪崩是指在同一时间,缓存中大量的缓存数据失效,导致大量的请求直接打到了后端数据库上,使得数据库瞬间达到峰值负载,甚至直接宕机。这种情况通常发生在缓存中的数据同时过期时间设置相同,同时失效的情况下。
为了避免缓存雪崩问题,可以采取以下措施:
- 给缓存数据的过期时间加上随机值,避免同时失效。
- 将缓存数据的过期时间分散开来,比如一部分设置为5分钟,一部分设置为10分钟,一部分设置为15分钟,以此类推。
- 设置本地缓存,当缓存失效时,先从本地缓存中获取数据,如果本地缓存没有,则去后端数据库取数据,并将数据再次缓存到本地缓存中。
5.2. 缓存击穿
缓存击穿是指某个热点key在缓存过期的同时,有大量的请求访问该key的时候,这些请求直接穿透到后端数据库,导致数据库瞬间达到峰值负载,甚至直接宕机。
为了避免缓存击穿问题,可以采取以下措施:
- 在缓存数据不存在时,不直接去查询后端数据库,而是先将该key设置为一个特殊的值(如null),在一段时间内(如5秒)不再查询后端数据库,从而避免瞬间大量请求打到数据库上。
- 设置热点数据永不过期,或者过期时间非常长,例如一天、一周、一个月等。
- 设置本地缓存,当缓存失效时,先从本地缓存中获取数据,如果本地缓存没有,则去后端数据库取数据,并将数据再次缓存到本地缓存中。
在使用Redis时需要注意缓存雪崩和缓存击穿问题,采取相应的措施可以避免这些问题的发生,提高系统的稳定性和可靠性。
在Redis中,缓存失效可能有以下几种情况:
- 过期时间到期:当设置了缓存的过期时间后,到期后缓存将会失效。
- 主动删除:使用
DEL命令或者程序中的delete方法,主动删除缓存。 - 内存空间不足:当Rediss内存空间不足时,Rediss会优先淘汰赛掉内存占用较大,使用较少的缓存,以腾出更多的内存空间。
- 内存泄漏:当程序中出现内存泄漏时,会导致缓存失效。
- Redis重启:当Redis服务重启时,缓存也会失效。
为了避免缓存失效,我们可以设置合适的缓存过期时间,定期检查和清理过期缓存,优化Redis的内存使用,以及避免内存泄漏等问题。
6. 在Spring Boot中使用Redis
Redis是一个流行的内存数据存储解决方案,它可以用作缓存、数据库和消息代理。在Spring Boot应用程序中使用Redis可以提高应用程序的性能和可扩展性。在本文中,我们将介绍如何在Spring Boot应用程序中使用Redis。
6.1. .添加Redis依赖
要在Spring Boot应用程序中使用Redis,我们首先需要添加Redis依赖,在Maven项目中,我们可以在pom. xml文件中添加以下依赖项:
1 | <dependency> |
6.2. 配置Redis连接
在我们可以使用Redis之前,我们需要配置Redis连接.在Spring Boot应用程序中,我们可以在application.properties文件中添加以下配置:
1 | spring.redis.host=localhost |
这将配置Redis连接到本地主机的默认端口6379。
6.3. 使用RedisTemplate
Spring Boot提供了一个RedisTemplate类,它是一个用于与Redis交互的高级API。我们可以使用RedisTemplate来执行Redis操作,如存储、检索和删除数据。以下是一个使用RedisTemplate执行Redis操作的示例:
1 | @Autowired |
在上面的示例中,我们注入了一个RedisTemplate对象,并使用它来存储和检索数据。我们使用opsForValue()方法来访问Redis值操作,如设置和获取值。
7. 使用注解
除了使用RedisTemplate之外,Spring Boot还提供了一些注解,可以更轻松地使用Redis。例如,我们可以使用@Cacheable注解将方法的结果缓存到Redis中,从而加快方法的执行速度。以下是一个使用@Cacheable注解的示例:
1 | @Cacheable(value = "users", key = "#userId") |
在上面的示例中,我们使用@Cache able注解将User By Id方法的结果缓存到名为”user”的Red is缓存中,缓存键为rId参数。
7.1. 常见客户端比较 lettuce ,redisson,jedis
| 特性 | Lettuce | Redisson | Jedis |
|---|---|---|---|
| 完整性 | Lettuce 是一个可扩展的线程安全 Redis 客户端,适用于同步、异步和反应式使用。 如果多个线程避免阻塞和事务性操作(例如 BLPOP 和 MULTI/EXEC),则它们可以共享一个连接。 Lettuce是用netty构建的。 支持高级 Redis 功能,例如 Sentinel、集群、管道、自动重新连接和 Redis 数据模型。 | Redisson提供了完整的Redis协议支持,基于Netty 框架,并在其基础上封装了更丰富的特性,如分布式锁、分布式集合等.线程安全的实现 支持Redis复制、Redis集群、Redis哨兵、Redis主从、Redis单机、Redis代理、Redis多集群设置 | Jedis提供了基本的Redis协议支持,但支持高级功能如Pipelining、Miscellaneous、Cluster、Pub/Sub等。Redis 官方推荐的Java客户端 |
| 连接管理 | 支持连接池和连接自动恢复机制,具有更好的连接管理能力。 | 支持连接池和连接自动恢复机制,具有较好的连接管理能力。 | 支持连接池,但没有连接自动恢复机制, |
| 异步操作 | 提供完善的异步操作接口和功能,支持Reactive编程模型。 | 提供完善的异步操作接口和功能,支持Reactive编程模型。 | 不支持异步操作,只能使用同步方式进行操作。 |
| 分布式功能 | 支持Redis Sentinel和Redis Cluster,可以使用Lettuce进行分布式部署。 | 提供了丰富的分布式功能,如分布式锁、分布式集合、分布式对象等。 | 不支持Redis Sentinel和Redis Cluster,不适用于分布式部署。 |
| 扩展性 | 提供了较好的扩展性,用户可以自定义编解码器、连接池实现等。 | 提供了较好的扩展性,用户可以自定义编解码器、连接管理器等。 | 较难进行扩展,功能相对固定。 |
| 社区活跃度 | 拥有活跃的开源社区,稳定更新并提供技术支持。 | 拥有活跃的开源社区,稳定更新并提供技术支持。 | 拥有较为活跃的开源社区,但相对于Lettuce和Redisson稍显不足。 |
| https://github.com/lettuce-io/lettuce-core最新版本是 | https://github.com/redisson/redisson 最新版是 3.23.4 | https://github.com/redis/jedis 最近版本是5.0.0 |
8. 结论
在Spring Boot应用程序中使用Redis可以提高应用程序的性能和可扩展性。我们可以使用RedisTemplate类来执行Redis操作,也可以使用注解来更轻松地使用Redis。无论是存储会话数据还是缓存结果,Redis都是一个强大的解决方案。如果您正在使用Spring Boot,请考虑在应用程序中使用Redis。
Redis是一种开源内存数据存储解决方案,可用作缓存、数据库和消息代理,其主要特点和原理包括:
- 内存存储: Redis将所有数据存储在内存中,以便快速读写访问。它还支持各种数据结构,例如字符串、哈希、列表、集合和排序集合。
- 持久化:Redis支持将数据持久化到磁盘,以实现可靠的存储和恢复。 它提供两种不同的持久性选项:快照和日志。
- 高可用性:Redis支持主从复制和哨兵机制,实现高可用性和故障点转移。
- 分布式:Redis Cluster可以将数据分布在多个节点上,以实现水平扩展和高性能。
- 事务和Lua脚本: Redis支持原子操作和自定义命令的事务和Lua脚本。
总体而言,Redis的主要特点是速度、可靠性和可扩展性.广泛应用于缓存、会话存储、消息队列、计数器、排行榜等各种应用场景。
与MongoDB相比,Redis是一种专门的内存数据存储,而MongoDB是一种通用的面向文档的数据库。对于读取密集型工作负载,Redis比MongoDB更快,而MongoDB更适合写入密集型工作负载。Redis由于依赖内存,存储容量有限,而MongoDB可以水平扩展以处理大量数据。
与常见的关系数据库和图数据库相比,Redis由于其内存存储和简单的数据结构,在读写性能上更快。
Redis的一些优点包括速度,简单性和灵活性.它易于使用,可用于广泛的数据存储和处理任务.它的一些缺点包括对内存的依赖,存储容量有限以及缺乏对复杂查询和连接的支持。
Redis是一种开源内存数据存储解决方案,可用作缓存、数据库和消息代理,其主要特点和原理包括:
- 内存存储: Redis将所有数据存储在内存中,以便快速读写访问。它还支持各种数据结构,例如字符串、哈希、列表、集合和排序集合。
- 持久化:Redis支持将数据持久化到磁盘,以实现可靠的存储和恢复。 它提供两种不同的持久性选项:快照和日志。
- 高可用性:Redis支持主从复制和哨兵机制,实现高可用性和故障点转移。
- 分布式:Redis Cluster可以将数据分布在多个节点上,以实现水平扩展和高性能。
- 事务和Lua脚本: Redis支持原子操作和自定义命令的事务和Lua脚本。
总体而言,Redis的主要特点是速度、可靠性和可扩展性.广泛应用于缓存、会话存储、消息队列、计数器、排行榜等各种应用场景。
与MongoDB相比,Redis是一种专门的内存数据存储,而MongoDB是一种通用的面向文档的数据库。对于读取密集型工作负载,Redis比MongoDB更快,而MongoDB更适合写入密集型工作负载。Redis由于依赖内存,存储容量有限,而MongoDB可以水平扩展以处理大量数据。
与常见的关系数据库和图数据库相比,Redis由于其内存存储和简单的数据结构,在读写性能上更快。
Redis的一些优点包括速度,简单性和灵活性.它易于使用,可用于广泛的数据存储和处理任务.它的一些缺点包括对内存的依赖,存储容量有限以及缺乏对复杂查询和连接的支持。
8.1. 常见的用途
- 同步session
- 分布式事务锁或者是 lock
- 注册中心
- 缓存中间件
- 触发器,订阅-触发的同步机制
在Spring Boot应用程序中使用Redis可以提高应用程序的性能和可扩展性。我们可以使用RedisTemplate类来执行Redis操作,也可以使用注解来更轻松地使用Redis。无论是存储会话数据还是缓存结果,Redis都是一个强大的解决方案。如果您正在使用Spring Boot,请考虑在应用程序中使用Redis。
Redis是一种开源内存数据存储解决方案,可用作缓存、数据库和消息代理,其主要特点和原理包括:
- 内存存储: Redis将所有数据存储在内存中,以便快速读写访问。它还支持各种数据结构,例如字符串、哈希、列表、集合和排序集合。
- 持久化:Redis支持将数据持久化到磁盘,以实现可靠的存储和恢复。 它提供两种不同的持久性选项:快照和日志。
- 高可用性:Redis支持主从复制和哨兵机制,实现高可用性和故障点转移。
- 分布式:Redis Cluster可以将数据分布在多个节点上,以实现水平扩展和高性能。
- 事务和Lua脚本: Redis支持原子操作和自定义命令的事务和Lua脚本。
总体而言,Redis的主要特点是速度、可靠性和可扩展性.广泛应用于缓存、会话存储、消息队列、计数器、排行榜等各种应用场景。
与MongoDB相比,Redis是一种专门的内存数据存储,而MongoDB是一种通用的面向文档的数据库。对于读取密集型工作负载,Redis比MongoDB更快,而MongoDB更适合写入密集型工作负载。Redis由于依赖内存,存储容量有限,而MongoDB可以水平扩展以处理大量数据。
与常见的关系数据库和图数据库相比,Redis由于其内存存储和简单的数据结构,在读写性能上更快。
Redis的一些优点包括速度,简单性和灵活性.它易于使用,可用于广泛的数据存储和处理任务.它的一些缺点包括对内存的依赖,存储容量有限以及缺乏对复杂查询和连接的支持。
Redis是一种开源内存数据存储解决方案,可用作缓存、数据库和消息代理,其主要特点和原理包括:
- 内存存储: Redis将所有数据存储在内存中,以便快速读写访问。它还支持各种数据结构,例如字符串、哈希、列表、集合和排序集合。
- 持久化:Redis支持将数据持久化到磁盘,以实现可靠的存储和恢复。 它提供两种不同的持久性选项:快照和日志。
- 高可用性:Redis支持主从复制和哨兵机制,实现高可用性和故障点转移。
- 分布式:Redis Cluster可以将数据分布在多个节点上,以实现水平扩展和高性能。
- 事务和Lua脚本: Redis支持原子操作和自定义命令的事务和Lua脚本。
总体而言,Redis的主要特点是速度、可靠性和可扩展性.广泛应用于缓存、会话存储、消息队列、计数器、排行榜等各种应用场景。
与MongoDB相比,Redis是一种专门的内存数据存储,而MongoDB是一种通用的面向文档的数据库。对于读取密集型工作负载,Redis比MongoDB更快,而MongoDB更适合写入密集型工作负载。Redis由于依赖内存,存储容量有限,而MongoDB可以水平扩展以处理大量数据。
与常见的关系数据库和图数据库相比,Redis由于其内存存储和简单的数据结构,在读写性能上更快。
Redis的一些优点包括速度,简单性和灵活性.它易于使用,可用于广泛的数据存储和处理任务.它的一些缺点包括对内存的依赖,存储容量有限以及缺乏对复杂查询和连接的支持。
8.1. 常见的用途
- 同步session
- 分布式事务锁或者是 lock
- 注册中心
- 缓存中间件
- 触发器,订阅-触发的同步机制

