
kafka开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。这是维基百科上的描述,这也是区别于rabbitmq等其他的消息队列的特点,kafka基于订阅-消费模式,自定义的协议,不同于MQTT,AMPQ,JMS等这些协议
- Provider/MessageProvider:生产者
- Consumer/MessageConsumer:消费者
- PTP:Point To Point,点对点通信消息模型
- Pub/Sub:Publish/Subscribe,发布订阅消息模型
- Queue:队列,目标类型之一,和PTP结合
- Topic:主题,目标类型之一,和Pub/Sub结合
- ConnectionFactory:连接工厂,JMS用它创建连接
- Connnection:JMS Client到JMS Provider的连接
- Destination:消息目的地,由Session创建
- Session:会话,由Connection创建,实质上就是发送、接受消息的一个线程,因此生产者、消费者都是Session创建的
值得注意的是 在kafka中需要注意的名词包括 broke,topic,producer,consumer,partition,replica
类似的
图解相关的kafka概念
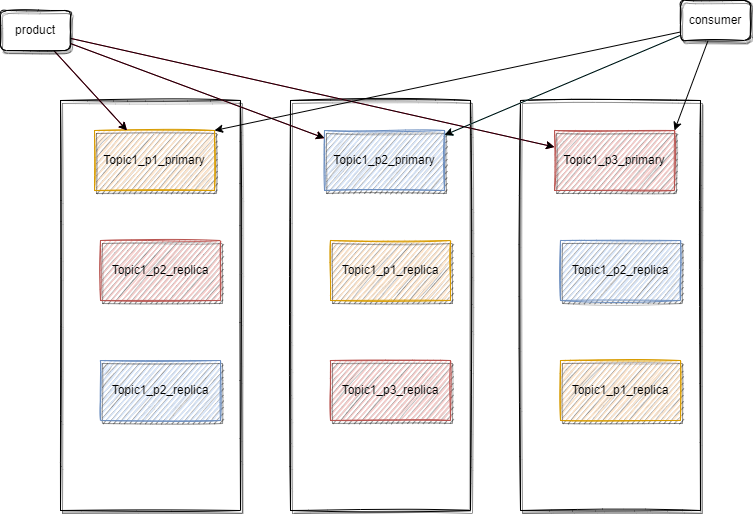
leader,follower同步过程中截断机制
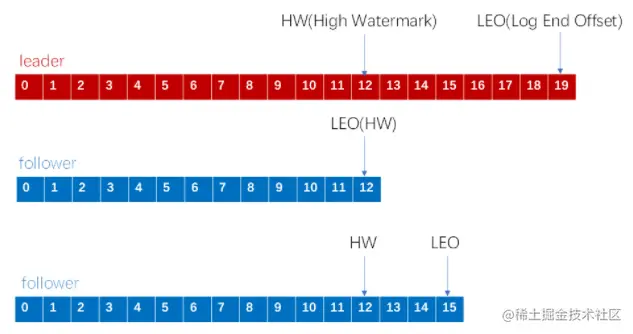
注意在消费中HW(High Watermark).LEO(Log End Offset),在ISR(in-sync replica )列表需要保持hw一致,在leader变更中需要注意leo,HW(High Watermark)是所有副本中最小的LEO。
针对kafka的幂等性PID(Producer ID)和sequence numbers。
product会维护一个生产序列seq来表现.如果对应的seq和broke的对不上
product_seq>broke_seq 消息丢失
product_seq<broke_seq+1 重复保存
参考链接:Kafka的ISR机制+日志数据清理 - 掘金,MQ(消息队列)的使用场景以及常见的MQ - 邓维-java - 博客园

