–2022-7-7补充
GeoQuery(一)-html
Lucene Spatial构建地理空间索引 - 韩要奋斗 - 博客园
Lucene下面关于地理信息的内容
lucene多条件查询_三天打鱼_的博客-CSDN博客_lucene多条件查询
lucene和ik分词器
使用Lucene-Spatial实现集成地理位置的全文检索 - 刺猬的温驯 - 博客园
Springboot下的Lucene(详细版)_程序猿开发日志【学习永无止境】-CSDN博客
Lucene搭建搜索引擎初探 | 大嘴怪的小世界
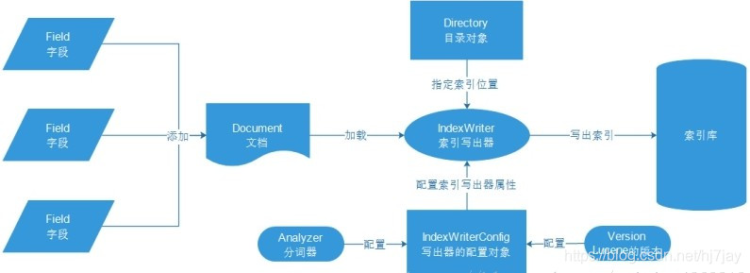
索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
https://hub.fastgit.org/blueshen/ik-analyzer.git 使用的ik分词器地址同时
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| <properties>
<lucene.version>7.2.1</lucene.version>
</properties>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-test-framework</artifactId>
<version>${lucene.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.wltea.ik-analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>9.0.0</version>
</dependency>
|
使用luke来查询索引的数据
lucene集成ik和pinyin分词器
pinyin4j-2.5.1.jar
pinyinAnalyzer4.3.1.jar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <dependency>
<groupId>com.belerweb</groupId>
<artifactId>pinyin4j</artifactId>
<version>2.5.1</version>
<systemPath>${pom.basedir}/src/main/resources/lib/pinyin4j-2.5.1.jar</systemPath>
</dependency>
<dependency>
<groupId>com.shentong</groupId>
<artifactId>pinyinAnalyzer</artifactId>
<version>4.3.1</version>
<scope>system</scope>
<systemPath>${pom.basedir}/src/main/resources/lib/pinyinAnalyzer4.3.1.jar</systemPath>
</dependency>
|
该部分参考
实现的原理就是使用创建个 IndexPinyinAnalyzer 使用IKTokenizer 和PinyinTransformTokenFilter实现分词汉字和拼音的效果
测试的部分代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public static void main(String[] args) throws IOException {
Analyzer analyzer = new IndexPinyinAnalyzer(false);
TokenStream tokenStream = analyzer.tokenStream("fff", "标高1-KL33");
//添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//添加一个偏移量的引用,记录了关键词的开始位置以及结束位置
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
//将指针调整到列表的头部
tokenStream.reset();
//遍历关键词列表,通过incrementToken方法判断列表是否结束
while(tokenStream.incrementToken()) {
//关键词的起始位置
System.out.println("start---------------" + offsetAttribute.startOffset());
//取关键词
System.out.println("分词内容: "+charTermAttribute);
//结束位置
System.out.println("end---------------------" + offsetAttribute.endOffset());
}
tokenStream.close();
}
|
打印结果
start—————0
分词内容标高
end———————2
start—————0
分词内容bg
end———————2
start—————2
分词内容1-kl33
end———————8
start—————4
分词内容kl
end———————6
start—————6
分词内容33
end———————8
需要注意几点
- pinyin4j 需要是2.5.1
- 分词和使用的dic有关,笔者使用的默认值,在日志中会打印org.wltea.analyzer.dic.Dictionary - 加载扩展停止词典:org/wltea/analyzer/dic/stopword.dic


